Highlights:
|
Five Arguments for Intelligent Design
1. Proteins: the Case for Intelligent Design

This is what a real protein looks like. The enzyme hexokinase is a protein found even in simple bacteria. Here, it is shown as a conventional ball-and-stick molecular model. For the purposes of comparison, the image also shows molecular models of ATP (an energy carrier found in the cells of all known organisms) and glucose (the simplest kind of sugar) in the top right-hand corner. Courtesy of Tim Vickers and Wikipedia.
|
Argument One: The Origin of Proteins
The Argument in a Nutshell: Every living thing on this planet contains proteins, which are made up of amino acids. Proteins are fundamental components of all living cells and include many substances, such as enzymes, hormones, and antibodies, that are necessary for the proper functioning of an organism. They're involved in practically all biological processes. To fulfil their tasks, proteins need to be folded into a complicated three-dimensional structure. Proteins can tolerate slight changes in their amino acid sequences, but a single change of the wrong kind can render them incapable of folding up, and hence, totally incapable of doing any kind of useful work within the cell. That's why not every amino-acid sequence represents a protein: only one that can fold up properly and perform a useful function within the cell can be called a protein. Now let's consider a protein made up of 150 amino acids - which is a fairly modest length. If we compare the number of 150-amino-acid sequences that correspond to some sort of functional protein to the total number of possible 150-amino-acid sequences, we find that only a tiny proportion of possible amino acid sequences are capable of performing a function of any kind. The vast majority of amino-acid sequences are good for nothing. So, what proportion of amino acid sequences are capable of doing something useful? An astronomically low proportion: 1 in 10 to the power of 74, according to work done by Dr. Douglas Axe. When we add the requirement that a protein has to be made up of amino acids that are either all left-handed or all right-handed, and when we finally add the requirement that the amino acids have to be held together by peptide bonds, we find that only 1 in 10 to the power of 164 amino-acid sequences of that length are suitable proteins. 1 in 10 to the power of 164 is 1 in 1 followed by 164 zeroes. The Earth has been around for 4,500,000,000 years, but it should be obvious to the reader that that's nowhere near enough time for a protein to form as a result of unguided natural processes.
The Argument in More Detail: The following passage is taken from Dr. Stephen Meyer's book, Signature in the Cell (HarperOne, 2009). On pages 210-213, Myer discusses the "pure chance" hypothesis for the origin of life. He begins by calculating the odds of obtaining even a single functional protein, of any kind, over the time period that the Earth has existed.
[B]y taking what he knew about protein folding into acocunt, Axe estimated the ratio of (a) the number of 150-amino-acid sequences that produce any functional protein whatsoever to (b) the whole set of possible amino-acide sequences of that length. Axe's estimated ratio of 1 in 10^74 implied that the probability of producing any properly sequenced 150-amino-acid protein at random is also about 1 in 10^74. In other words, a random process producing amino-acid chains of this length would stumble onto a functional protein only about once in every 10^74 attempts...
|
|
Objection: You mentioned Dr. Douglas Axe. Who is he? Is he a qualified scientist? Reply: Yes, he is. Dr. Douglas Axe is the director of the Biologic Institute. His research uses both experiments and computer simulations to examine the functional and structural constraints on the evolution of proteins and protein systems. After obtaining a Caltech Ph.D., he held postdoctoral and research scientist positions at the University of Cambridge, the Cambridge Medical Research Council Centre, and the Babraham Institute in Cambridge. He has also written two articles for the Journal of Molecular Biology (see here and here for abstracts). He has also co-authored an article published in the Proceedings of the National Academy of Sciences, an article in Biochemistry and an article published in PLoS ONE. His work has been reviewed in Nature and featured in a number of books, magazines and newspaper articles, including Life's Solution by Simon Conway Morris, The Edge of Evolution by Michael Behe, and Signature in the Cell by Stephen Meyer. Objection: Plant biologist Art Hunt has claimed that Douglas Axe's 2004 paper in the Journal of Molecular Biology doesn't claim to support Intelligent Design or challenge Darwinism, so it's a mistake to use it for those purposes. Reply: Dr. Douglas Axe himself has rebutted this claim in his article, Correcting Four Misconceptions about my 2004 Article in JMB (May 4, 2011).
|
|
Objection: Your argument against the possibility of proteins forming appeals to chance processes alone: it assumes that all amino acid sequences are equally likely. But why couldn't a combination of chance plus necessity improve the likelihood of proteins forming? Maybe there are hidden laws of chemical affinity, which would have favored the evolution of proteins on the primordial Earth. Given enough time and a suitable planet like ours, it could have happened.
Reply: (2) In any case, there is very strong experimental evidence that for complex molecules such as DNA, RNA and proteins, there are no stringent chemical constraints on chaining that would be sufficient to account for the information contained in these chains. This was already investigated by Bradley et al. in the mid 1980s, and it's a major reason why Professor Dean Kenyon (who is Professor Emeritus of biology at San Francisco State University, and the author of a text called Biochemical Predestination) chose to take the opportunity of publicly recanting from biochemical predestination in the preface he wrote for the first technical work on Intelligent Design: a book titled, The Mystery of Life's Origin by Charles B. Thaxton, Walter L. Bradley and Roger L. Olson. (3) Even if biochemical predestination were true, it would only boost the argument for a Designer. Here's why. We already know that if the constants of Nature were a little different, carbon-based life would be impossible. If biochemical predestination were true, it would mean that the universe is even more life-friendly than we imagined. If biochemistry and life-functional DNA and/or protein chains are written into the underlying physics that drives the creation, abundance and environments of H, He, C, O and N — the main atoms involved — then that would be the ultimate proof that the laws of physics are a program designed to create life.
|
|
Objection: What about the RNA world scenario? Your argument assumes that proteins formed as a direct result of amino acids linking together into longer and longer sequences. Most scientists now believe that it didn't happen that way. They believe that another molecule - RNA - formed first, and that proteins were formed from that molecule. Reply: The same problem arises for RNA: the vast majority of possible sequences are non-functional, and only an astronomically tiny proportion work. Robert Shapiro (1935-2011) was professor emeritus of chemistry at New York University. In a discussion hosted by Edge in 2008, entitled, Life! What a Concept, with scientists Freeman Dyson, Craig Venter, George Church, Dimitar Sasselov and Seth Lloyd, Professor Shapiro explained why he found the RNA world hypothesis incredible:
... I looked at the papers published on the origin of life and decided that it was absurd that the thought of nature of its own volition putting together a DNA or an RNA molecule was unbelievable.
|
Recommended Reading
How can we account for the origin of proteins that could fold and perform useful tasks? In a recent article, Dr. Douglas Axe has argued that we should be looking well outside the Darwinian framework for an adequate explanation of protein fold origins. The following excerpt is taken from Dr. Douglas Axe's article, The Case Against a Darwinian Origin of Protein Folds, in BioComplexity 2010(1):1-12. doi:10.5048/BIO-C.2010.1
AbstractFour decades ago, several scientists suggested that the impossibility of any evolutionary process sampling anything but a miniscule fraction of the possible protein sequences posed a problem for the evolution of new proteins. This potential problem-the sampling problem-was largely ignored, in part because those who raised it had to rely on guesswork to fill some key gaps in their understanding of proteins. The huge advances since that time call for a careful reassessment of the issue they raised. Focusing specifically on the origin of new protein folds, I argue here that the sampling problem remains. The difficulty stems from the fact that new protein functions, when analyzed at the level of new beneficial phenotypes, typically require multiple new protein folds, which in turn require long stretches of new protein sequence. Two conceivable ways for this not to pose an insurmountable barrier to Darwinian searches exist. One is that protein function might generally be largely indifferent to protein sequence. The other is that relatively simple manipulations of existing genes, such as shuffling of genetic modules, might be able to produce the necessary new folds. I argue that these ideas now stand at odds both with known principles of protein structure and with direct experimental evidence. If this is correct, the sampling problem is here to stay, and we should be looking well outside the Darwinian framework for an adequate explanation of fold origins.
Excerpt from the paper:
"Based on analysis of the genomes of 447 bacterial species, the projected number of different domain structures per species averages 991. Comparing this to the number of pathways by which metabolic processes are carried out, which is around 263 for E. coli, provides a rough figure of three or four new domain folds being needed, on average, for every new metabolic pathway. In order to accomplish this successfully, an evolutionary search would need to be capable of locating sequences that amount to anything from one in 10^159 to one in 10^308 possibilities, something the neo-Darwinian model falls short of by a very wide margin." (p. 11)
2. The Origin of the First Living Cell: the Case for Intelligent Design
 |
|

Left: A game of Scrabble. Professor Dr. Robert Shapiro (1935-2011), who was professor emeritus of chemistry at New York University, has declared: "[S]uppose you took Scrabble sets, or any word game sets, blocks with letters, containing every language on Earth, and you heap them together and you then took a scoop and you scooped into that heap, and you flung it out on the lawn there, and the letters fell into a line which contained the words 'To be or not to be, that is the question,' that is roughly the odds of an RNA molecule ... appearing on the Earth."
Right: Diagram of a typical prokaryotic cell (e.g. a simple bacterium). Courtesy of Lady of Hats and Wikipedia.
|
Argument Two: The Origin of Life
The Argument in a Nutshell:
Even a minimally complex cell needs at least 250 proteins, for it to work. If the odds of generating even one protein by blind processes during the 4.5-billion-year history of the Earth are astronomically low, then the odds of generating a living cell are much, much worse. Finally, some scientists have proposed that the first living things were made of something more exotic than DNA or RNA - maybe clay crystals. But once again, that's pure supposition, which isn't backed up by any hard evidence.
The argument in more detail: The astronomical improbability of the cell, or: why Fred Hoyle was right! Above, I quoted a passage taken from pages 210-213 of Dr. Stephen Meyer's best-selling book, Signature in the Cell (Harper One, 2009), where he calculated the odds of getting even a single functional protein, of any kind, over the time period that the Earth has existed: about 1 in 10 to the power of 164. In the passage below, Dr. Meyer explains how the astronomical odds against even one protein forming as a result of unguided processes puts the origin of life from non-living matter (abiogenesis) out of the question:
The probability of finding a functional protein by chance alone is a trillion, trillion, trillion, trillion, trillion, trillion, trillion times smaller than the odds of finding a single specified particle among all the particles in the universe. Meyer's last sentence should suffice to refute claims made on the Internet that the 1 in 10^164 estimate for the likelihood of a single functional protein arising by chance is far too pessimistic. Even if we revise the estimate by dozens of orders of magnitude, we are still left with an astronomically improbable event, for a cell which requires 250 functional proteins.
|
|
Why life had to have been designed: the video that tells it all Professor John C. Walton is a Research Professor of Chemistry at St. Andrews University, and a Chartered Chemist. He is a Fellow of the Royal Society of Chemistry, and also a Fellow of the Royal Society of Edinburgh. Professor Walton made his views on the origin of life public in a recent talk for the Edinburgh Creation Group entitled, The Origin of Life, given on September 21, 2010, and available online at http://vimeo.com/415018 .
The Origin of Life from Phil Holden on Vimeo.
(VERY IMPORTANT: Before you play this video, press the PAUSE button and wait about two minutes, until the gray bar at the bottom has finished scrolling across to the right. Then press the PLAY button to start the video. Enjoy!) Or watch the video on this link. Highlights of Professor Walton's talk
|
|
Objection: The origin of life is not a problem for Darwinism. Reply: That's an often-repeated "party line," but it's false. Writing in The Scientist (20 June 2008), Gordy Slack acknowledged in an article entitled, What neo-creationists get right:
First, I have to agree with the ID crowd that there are some very big (and frankly exciting) questions that should keep evolutionists humble. While there is important work going on in the area of biogenesis, for instance, I think it's fair to say that science is still in the dark about this fundamental question. It's hard to draw conclusions about the significance of what we don't know. Still, I think it is disingenuous to argue that the origin of life is irrelevant to evolution. It is no less relevant than the Big Bang is to physics or cosmology. Evolution should be able to explain, in theory at least, all the way back to the very first organism that could replicate itself through biological or chemical processes. And to understand that organism fully, we would simply have to know what came before it. And right now we are nowhere close. I believe a material explanation will be found, but that confidence comes from my faith that science is up to the task of explaining, in purely material or naturalistic terms, the whole history of life. My faith is well founded, but it is still faith.
|
|
Objection: If the first living things didn't contain proteins, then the problem of how 250 proteins could have spontaneously originated on the primordial Earth does not arise. Many scientists now accept the RNA world hypothesis, which proposes that life based on ribonucleic acid (RNA) pre-dates the current world of life based on deoxyribonucleic acid (DNA), RNA and proteins. Reply: If you watch the video by Professor John C. Walton above, you'll see why the RNA world hypothesis won't work. Unlike proteins, which are made up of amino acids, RNA is a long chain made up of nucleotides. Nevertheless, the same problem arises for RNA as for proteins: only an astronomically tiny proportion of possible sequences are capable of doing any biologically useful work, so the chances of a useful RNA molecule forming by blind processes are very, very low. The late Robert Shapiro (1935-2011) was professor emeritus of chemistry at New York University. In a discussion hosted by Edge in 2008, entitled, Life! What a Concept, with scientists Freeman Dyson, Craig Venter, George Church, Dimitar Sasselov and Seth Lloyd, Professor Shapiro explained why he found the RNA world hypothesis incredible:
... I got into the question of the origin of life, and knowing the DNA chemistry that I did know — and helped write — I looked at the papers published on the origin of life and decided that it was absurd that the thought of nature of its own volition putting together a DNA or an RNA molecule was unbelievable. The recent publication of new research (reorted in ScienceDaily, March 12, 2012) on the origin of the ribosome (a component of cells that synthesizes protein chains) deals a further blow to the RNA world scenario, which "posits that the first stages of molecular evolution involved RNA and not proteins, and that proteins (and DNA) emerged later," because it suggests that a large number of proteins were present in living things, right from the get-go: "according to a new analysis, even before the ribosome's many working parts were recruited for protein synthesis, proteins also were on the scene and interacting with RNA." Where did all these proteins come from? (For the original paper, see Ajith Harish, Gustavo Caetano-Anolles. "Ribosomal History Reveals Origins of Modern Protein Synthesis." PLoS ONE, 2012; 7(3): e32776. DOI: 10.1371/journal.pone.0032776.)
|
|
Objection: Could DNA (or RNA) have been biologically predestined to arise naturally, by a kind of chemical necessity? Reply: Biochemical predestination can be safely rejected for DNA, for reasons explained by Dr. Stephen Meyer in his book, Signature in the Cell (HarperOne, 2009):
In sum, two features of DNA ensure that "self-organizing" bonding affinities cannot explain the specific arrangement of nucleotides in the molecule: (1) there are no bonds between bases along the information-bearing axis of the molecule and (2) there are no differential affinities between the backbone and the specific bases that could account for variations in the sequence. (Meyer, 2009, p. 244) The same considerations apply to RNA.
|
|
Objection: Maybe the first living things were made up of much shorter molecules: polypeptides, or TNA.
Reply:
I asked him if it was proper to consider these molecules "life" and he shot back a resounding "No!" Nobody has even come close to creating what we would call life, according to Dr. Ghadiri... Finally, the Ghadiri polypeptide is incapable of undergoing Darwinian evolution. Even the smallest changes in structure would render it incapable of working as it does. (2) Recently, Yu et al. have suggested in a scientific article ("Darwinian evolution of an alternative genetic system provides support for TNA as an RNA progenitor", Nature Chemistry 2012, published online 10 January 2012, doi:10.1038/nchem.1241) that TNA may have acted as a precursor to RNA. First of all, this assumes that the RNA world hypothesis is true, which recent research shows is almost certainly not the case (see PLoS ONE, 2012; 7(3): e32776. DOI: 10.1371/journal.pone.0032776). Moreover, Yu's proposal leaves a lot of questions answered, as a recent critical review (February 3, 2012) in Evolution News and Views points out:
How would TNA be synthesized in an early-Earth environment? Heat vents, ice crystals, concentrated pools, magma, in an oxidizing or a reducing environment? Is TNA more stable than RNA? If so, is it stable enough not to decompose under harsh environmental conditions? How did TNA eventually convert into RNA or DNA and is this synthesis prohibitively complex for an early-Earth scenario? If the early Earth only had three bases, how did it eventually come up with a fourth? And, most importantly, how did the relationship among DNA, mRNA, tRNA, and proteins evolve and where does TNA figure in that process? (3) All the living things we know of contain very long digital code sequences. For instance, the shortest genome found in any free-living organism today is that of the bacterium, Mycoplasma genitalium . This genome has nearly 600,000 pairs of bases, or about 6,000,000 atoms. The DNA letters of the genome of Mycoplasma genitalium would span 147 pages, if they were printed in 10 point font. So far, scientists haven't been able to make a free-living organism with a genome shorter than that. So the hypothesis that the first living things were much shorter than they were today is unsupported by any evidence.
|
|
Objection: Maybe the first life was based on a fundamentally different kind of chemistry, such as clay. Reply: That's an interesting hypothesis. But if you want to call it a scientific hypothesis, you have to do the mathematical spadework and show that the formation of a clay molecule that was capable of performing a specific function was more probable than the formation of an RNA, DNA or protein molecule that could perform a useful function. Where are the numbers?
|
|
Objection: Anything is possible, given enough time. As Harvard biology Professor George Wald wrote about the beginning of life back in 1955:
"The time with which we have to deal is of the order of two billion years.... Given so much time the 'impossible' becomes possible, the possible probable, and the probable virtually certain. One has only to wait: time itself performs miracles." {George Wald, "The origin of Life", in The Physics and Chemistry of Life, 1955, p. 12.} Othe scientists have echoed the same sentiment:
"The other important requirement for the origin of life is plenty of time. The events necessary for the beginnings of life were extremely unlikely." {K. Arms and P. Camp, Biology, Holt Rinehart and Winston, 1979, p. 156.} Reply: The problem with this objection is that we don't have an infinite amount of time. We only have billions of years. Billions pale into insignificance, when compared to gazillions. 1 followed by 9 zeroes is nothing compared to 1 followed by 164 zeroes, let alone 1 followed by 41,000 zeroes.
|
Recommended Reading
Is Darwinian evolution capable of transforming a protein that performs one biological function into a different protein which is able to perform a brand new biological function? Recent evidence suggests that such transformations seldom, if ever, occur. The following excerpt is taken from a 2011 paper by Dr. Ann K. Gauger and Dr. Douglas D. Axe, entitled, The Evolutionary Accessibility of New Enzyme Functions: A Case Study from the Biotin Pathway (BIO-Complexity 2011(1):1-17. doi:10.5048/BIO-C.2011.1):
AbstractEnzymes group naturally into families according to similarity of sequence, structure, and underlying mechanism. Enzymes belonging to the same family are considered to be homologs — the products of evolutionary divergence, whereby the first family member provided a starting point for conversions to new but related functions. In fact, despite their similarities, these families can include remarkable functional diversity. Here we focus not on minor functional variations within families, but rather on innovations — transitions to genuinely new catalytic functions. Prior experimental attempts to reproduce such transitions have typically found that many mutational changes are needed to achieve even weak functional conversion, which raises the question of their evolutionary feasibility. To further investigate this, we examined the members of a large enzyme superfamily, the PLP-dependent transferases, to find a pair with distinct reaction chemistries and high structural similarity. We then set out to convert one of these enzymes, 2-amino-3-ketobutyrate CoA ligase (Kbl2), to perform the metabolic function of the other, 8-amino-7-oxononanoate synthase (BioF2). After identifying and testing 29 amino-acid changes, we found three groups of active-site positions and one single position where Kbl2 side chains are incompatible with BioF2 function. Converting these side chains in Kbl2 makes the residues in the active-site cavity identical to those of BioF2, but nonetheless fails to produce detectable BioF2-like function in vivo. We infer from the mutants examined that successful functional conversion would in this case require seven or more nucleotide substitutions. But evolutionary innovations requiring that many changes would be extraordinarily rare, becoming probable only on timescales much longer than the age of life on earth. Considering that Kbl2 and BioF2 are judged to be close homologs by the usual similarity measures, this result and others like it challenge the conventional practice of inferring from similarity alone that transitions to new functions occurred by Darwinian evolution.
Excerpt from the paper:
The extent to which Darwinian evolution can explain enzymatic innovation seems, on careful inspection, to be very limited. Large-scale innovations that result in new protein folds appear to be well outside its range [5]. This paper argues that at least some small-scale innovations may also be beyond its reach.
A critical review of the paper by Professor P. Z. Myers
How not to examine the evolution of proteins by P.Z. Myers (October 20, 2011). A response to Gauger and Axe's paper.
How to examine the evolution of proteins by P.Z. Myers (October 20, 2011). A second response to Gauger and Axe's paper.
A Reply by Dr. Ann Gauger
On Protein Evolution, PZ Myers Is Way Off the Mark by Ann Gauger (October 26, 2011). A reply to Professor P. Z. Myers.
3. Molecular machines: the Case for Intelligent Design

|
The ribosome is found in all living things. It's a vital component of cells, and it synthesizes protein chains. This is a picture of just part of a ribosome. It shows the atomic structure of the 50S Subunit from the halobacterium Haloarcula marismortui. Proteins are shown in blue and the two RNA strands in orange and yellow. The small patch of green in the center of the subunit is the active site. Image courtesy of Wikipedia.
|
Argument Three: Molecular Machines
The Argument in a Nutshell: Most cellular functions are executed by complexes containing multiple proteins. These proteins work together in sync, acting like molecular machines. A molecular machine is an assemblage of parts that transmit energy from one to another in a predetermined manner. In living things - even the simplest ones - these machines are each composed of dozens or even hundreds of protein components. If the odds of generating even one functional protein by blind processes are astronomically low, the odds of making a molecular machine are unimaginably low.
|
|
Objection: We have indirect but very powerful evidence that these molecular machines evolved. These molecular machines must have once been simpler than they are now, because some of the proteins in a machines appear to have been derived from other ones in the same machine. Reply: I'm not arguing that molecular machines are the same as they originally were, and I'm happy to concede that they've undergone some degree of evolution. Nor am I attempting to argue that these machines are irreducibly complex, as I'm not a scientist. I'll leave that argument to qualified biochemists, such as Professor Michael Behe. All I'm concerned to show here is that even in their original form, these machines must have contained a large number of proteins. That's all. Even when you take out the obviously derived proteins that came along later, you're still stuck with machines that have dozens of component proteins. So the problem remains. Where did all these proteins come from?
|
|
Objection: What about the recent publication of new research (reorted in ScienceDaily, March 12, 2012), showing some of the key steps by which the ribosome (pictured above) originated? (For the original paper, see Ajith Harish, Gustavo Caetano-Anolles. "Ribosomal History Reveals Origins of Modern Protein Synthesis." PLoS ONE, 2012; 7(3): e32776. DOI: 10.1371/journal.pone.0032776.) Reply: Intelligent Design proponents welcome the publication of such research - otherwise I wouldn't be publicizing it here. But it actually highlights the problem I've been talking about, because it suggests that a large number of proteins were present in living things, right from the get-go: "according to a new analysis, even before the ribosome's many working parts were recruited for protein synthesis, proteins also were on the scene and interacting with RNA." Where did all these proteins come from? The new findings also pose a direct challenge to the long-dominant "RNA world" hypothesis, which "posits that the first stages of molecular evolution involved RNA and not proteins, and that proteins (and DNA) emerged later." In short: the new paper is a major boon for the Intelligent Design proponents.
|
Follow-up Questions
1. Can you give me a precise definition of a molecular machine?
Happy to oblige. Casey Luskin discusses the concept of a molecular machine in an online article entitled, Molecular Machines in the Cell (June 11, 2010), written for the Discovery Institute:
Long before the advent of modern technology, students of biology compared the workings of life to machines.1 In recent decades, this comparison has become stronger than ever. As a paper in Nature Reviews Molecular Cell Biology states, "Today biology is revealing the importance of 'molecular machines' and of other highly organized molecular structures that carry out the complex physico-chemical processes on which life is based."2 Likewise, a paper in Nature Methods observed that "[m]ost cellular functions are executed by protein complexes, acting like molecular machines."3 ...A molecular machine, according to an article in the journal Accounts of Chemical Research, is "an assemblage of parts that transmit forces, motion, or energy from one to another in a predetermined manner."4 A 2004 article in Annual Review of Biomedical Engineering asserted that "these machines are generally more efficient than their macroscale counterparts," further noting that "[c]ountless such machines exist in nature."5 Indeed, a single research project in 2006 reported the discovery of over 250 new molecular machines in yeast alone!6 ...
In 1998, former president of the U.S. National Academy of Sciences Bruce Alberts wrote the introductory article to an issue of Cell, one of the world's top biology journals, celebrating molecular machines. Alberts praised the "speed," "elegance," "sophistication," and "highly organized activity" of "remarkable" and "marvelous" structures inside the cell. He went on to explain what inspired such words:
The entire cell can be viewed as a factory that contains an elaborate network of interlocking assembly lines, each of which is composed of a set of large protein machines. . . . Why do we call the large protein assemblies that underlie cell function protein machines? Precisely because, like machines invented by humans to deal efficiently with the macroscopic world, these protein assemblies contain highly coordinated moving parts.9Likewise, in 2000 Marco Piccolini wrote in Nature Reviews Molecular Cell Biology that "extraordinary biological machines realize the dream of the seventeenth-century scientists ... that 'machines will be eventually found not only unknown to us but also unimaginable by our mind.'" He notes that modern biological machines "surpass the expectations of the early life scientists."10...
2. Can you give me a list of molecular machines?
There are literally thousands of these molecular machines in Nature. You'll find a list of about 40 molecular machines in Casey Luskin's online article, Molecular Machines in the Cell (June 11, 2010), written for the Discovery Institute. Here's a short selection of some of the best cases:
5. Ribosome: The ribosome is an "RNA machine"27 that "involves more than 300 proteins and RNAs"28 to form a complex where messenger RNA is translated into protein, thereby playing a crucial role in protein synthesis in the cell. Craig Venter, a leader in genomics and the Human Genome Project, has called the ribosome "an incredibly beautiful complex entity" which requires a "minimum for the ribosome about 53 proteins and 3 polynucleotides," leading some evolutionist biologists to fear that it may be irreducibly complex.297. Spliceosome: The spliceosome removes introns from RNA transcripts prior to translation. According to a paper in Cell, "In order to provide both accuracy to the recognition of reactive splice sites in the pre-mRNA and flexibility to the choice of splice sites during alternative splicing, the spliceosome exhibits exceptional compositional and structural dynamics that are exploited during substrate-dependent complex assembly, catalytic activation, and active site remodeling."34 A 2009 paper in PNAS observed that "[t]he spliceosome is a massive assembly of 5 RNAs and many proteins"35 — another paper suggests "300 distinct proteins and five RNAs, making it among the most complex macromolecular machines known."36
8. F0F1 ATP Synthase: According to cell biologist and molecular machine modeler David Goodsell, "ATP synthase is one of the wonders of the molecular world."37 This protein-based molecular machine is actually composed of two distinct rotary motors which joined by a stator: As the F0 motor is powered by protons, it turns the F1 motor. This kinetic energy is used like a generator to synthesize adenosine triphosphate (ATP), the primary energy carrying molecule of cells.38
15. Proteosome: The proteosome is a large molecular machine whose parts must be must be carefully assembled in a particular order. For example, the 26S proteosome has 33 distinct subunits which enable it to perform its function to degrade and destroy proteins that have been misfolded in the cell or otherwise tagged for destruction.50 One paper suggested that a particular eukaryotic proteasome "is the core complex of an energy-dependent protein degradation machinery that equals the protein synthesis machinery in its complexity."51
31. DNA Polymerase: The DNA polymerase is a multiprotein machine that creates a complementary strand of DNA from a template strand.73 The DNA polymerase is not only the "central component of the DNA replication machinery,"74 but it "plays the central role in the processes of life,"75 since it is responsible for the copying of DNA from generating to generation. During the polymerization process, it remains tethered to the DNA using a protein-based sliding clamp.76 It is extremely accurate, making less than one mistake per billion bases, aided by its ability to proofread and fix mistakes.77
33. Kinetochore: The kinetochore is a "proteinaceous structure that assembles on centromeric chromatin and connects the centromere to spindle microtubules."80 Called a "macromolecular protein machine,"81 it is composed of over 80 protein components;82 it aids in separating chromosomes during cell division.
40. Photosynthetic system: The processes that plants use to convert light into chemical energy a type of molecular machines.95 For example, photosystem 1 contains over three dozen proteins and many chlorophyll and other molecules which convert light energy into useful energy in the cell. "Antenna" molecules help increase the amount of light aborbed.96 Many complex molecules are necessary for this pathway to function properly.
Note: References are provided below, in the footnotes to this page.
4. Eukaryotic Cells: the Case for Intelligent Design

A plant cell is one kind of eukaryotic cell. Eukaryotic cells contain a nucleus. Bacterial cells, which are prokaryotic, do not. As we have seen, the emergence of even a humble bacterial cell as a result of blind natural processes (chance plus necessity) is astronomically improbable; the appearance of a eukaryotic cell is much more improbable. Image courtesy of Lady of Hats and Wikipedia.
|
Argument Four: The Eukaryotic Cell
The Argument in a Nutshell: Plants, animals, fungi, slime moulds, protozoa and algae are all made up of eukaryotic cells, which contain a nucleus and a number of internal structures called organelles, as well as a cytoskeleton, made out of protein, which helps define the cell's organization and shape. A eukaryotic cell is like a miniature factory. The cell nucleus contains a multitude of robot-like machines working in synchrony, which shuttle a huge range of products and raw materials along conduits leading to and from the various assembly plants in the outer parts of the cell. Everything is precisely choreographed. A eukaryotic cell exhibits features such as quality control, feedback systems and automated parcel processing ("zip codes"). What's more, each cell has to be capable of replicating its entire structure within just a few hours. To do all these things, a eukaryotic cell requires hundreds of different kinds of proteins: an evolutionist's nightmare.
|
|
Objection: Thanks to the work of the late Dr. Lynne Margulis, we now know that eukaryotic cells formed gradually in a step-by-step process called endosymbiosis, where some of the structures within the eukaryotic cell were once free-living bacteria that were taken inside another, bigger cell. In particular, scientists now know that mitochondria and chloroplasts arose in this way. Reply: That's true as far as it goes, but it still doesn't explain the origin of the nucleus of the eukaryotic cell, which is where most of the DNA resides. A nucleus requires hundreds of different kinds of proteins for it to do its work. That's what needs to be explained.
|
|
Objection: Hartman and Fedorov have addressed the origin of the nucleus, in their paper, The origin of the eukaryotic cell: A genomic investigation (Proceedings of the National Academy of Sciences USA, 2002 February 5; 99(3): 1420–1425. doi: 10.1073/pnas.032658599.) Reply: Hartman and Fedorov's paper actually refutes the dominant hypothesis for the formation of the nucleus of the eukaryotic cell - that it arose from the fusion of two simple prokaryotic cells (an archaeon and a bacterium), both of which lacked a nucleus. The authors correctly point out that this hypothesis leaves a lot unexplained: "a whole set of new cellular structures (i.e., endoplasmic reticulum, spliceosome, etc.) other than the cytoskeleton had to be constructed from prokaryotes that lacked them." Hartman and Fedorov also identified "a set of 347 proteins that are found in eukaryotic cells but have no significant homology to proteins in Archaea and Bacteria" [simpler life-forms which lack a nucleus in their cells - VJT]. No less than 254 of these proteins have an assigned function. To account for the origin of these proteins, the authors put forward a new proposal of their own: that the nucleus of the eukaryotic cell was formed when a number of archaea and bacteria (simple cells) were engulfed by a third kind of cell, which they refer to as a chronocyte. However, chronocytes do not exist in Nature today, and the authors freely acknowledge that their proposal is a "conjecture." What's more, as Hartman and Fedorov point out, this chronocyte would itself have been quite complex:
The chronocyte had a cytoskeleton that enabled it to engulf prokaryotic cells and a complex internal membrane system where lipids and proteins were synthesized. It also had a complex internal signaling system involving calcium ions, calmodulin, inositol phosphates, ubiquitin, cyclin, and GTP-binding proteins. Finally, the authors freely admit that the chronocyte, which they posit to account for the origin of the nucleus, would have required a large number of proteins, governing its membrane-protein-synthesizing machinery and cytoskeleton:
There was a complex inner membrane system where proteins were synthesized and broken down which eventually evolved into the ER, the GTP-binding proteins, ubiquitin, and the 11 ESP ribosomal proteins. This result is not a complete picture of the chronocyte, as we still cannot account for the functions of 93 ESPs [eukaryotic signature proteins - VJT]. In short: even if the authors' speculative proposal for the origin of the eukaryotic cell nucleus turns out to be correct, it still means that we are left with the problem of accounting for the origin of hundreds of proteins.
|
5. The Cambrian explosion: the Case for Intelligent Design


Left: Kimberella was about the most complex animal 555 million years ago. The only "advanced" feature about it was its bilateral symmetry. This animal had fewer than 10 cell types. Image courtesy of Nobu Tamura.
Right: Trilobites appeared 526 million years ago. These ones are from the Middle Cambrian period: a Elrathia kingii growth series, with specimens ranging from 16.2 mm to 39.8 mm. This animal probably had about 30 different cell types: a large jump. Image courtesy of John Alan Elson and Wikipedia.
|
Argument Five: Complex Animals
The Argument in a Nutshell:
Animals with complex body plans include arthropods, annelid worms, molluscs, echinoderms and chordates (the group that vertebrates belong to), as opposed to simple animals like sponges and coelenterates. Complex animals need more cell types in order to perform their diverse functions. New cell types require many new and specialized proteins. But these new proteins also have to be organized into new, hierarchically ordered systems within the cell. That's because in complex animals, new cell types need to be organized into new tissues, organs, and body parts, which in turn have to be organized to form body plans. In other words, complex animals embody hierarchically organized systems of lower-level parts within a functional whole. So we're not only talking about lots of proteins, we're talking about proteins organized into hierarchical levels of control. Once again, no evolutionist has put forward a quantifiable model of how these levels of control might have arisen.
The Argument in More Detail: All animals belong to about 30 basic types, or phyla, each with its own distinct body plan. Over a period of about 20 million years, from 540 to 520 million years ago, nearly all of these 30 different types of animals appeared in the geological record. 20 million years is a geological eye-blink: it represents about 0.4% of the Earth's geological history. Dr. Stephen Meyer explains why the relatively sudden appearance of these 30 different types of animals poses a giant problem for Darwinian evolution, in his 2004 article, Intelligent Design: The Origin of Biological Information and the Higher Taxonomic Categories, which was originally published in the Proceedings of the Biological Society of Washington (volume 117, no. 2, pp. 213-239):
Studies of modern animals suggest that the sponges that appeared in the late Precambrian, for example, would have required five cell types, whereas the more complex animals that appeared in the Cambrian (e.g., arthropods) would have required fifty or more cell types. Functionally more complex animals require more cell types to perform their more diverse functions. New cell types require many new and specialized proteins. New proteins, in turn, require new genetic information. Thus an increase in the number of cell types implies (at a minimum) a considerable increase in the amount of specified genetic information. Molecular biologists have recently estimated that a minimally complex single-celled organism would require between 318 and 562 kilobase pairs of DNA to produce the proteins necessary to maintain life (Koonin 2000). More complex single cells might require upward of a million base pairs. Yet to build the proteins necessary to sustain a complex arthropod such as a trilobite would require orders of magnitude more coding instructions. The genome size of a modern arthropod, the fruitfly Drosophila melanogaster, is approximately 180 million base pairs (Gerhart & Kirschner 1997:121, Adams et al. 2000). Transitions from a single cell to colonies of cells to complex animals represent significant (and, in principle, measurable) increases in CSI [complex specified information - VJT].
|
|
Objection: The Cambrian explosion is an illusion, caused by poorly preserved fossils. There were animals before the Cambrian, but they lacked hard parts, and thus never fossilized in the first place. The Cambrian explosion merely represents the sudden appearance of shells and skeletons in animal that had evolved long before. Reply: This is an old canard that you may have heard when you were in high school. Unfortunately for Darwinists, it's completely false. A Discovery Institute Briefing Paper, The Scientific Controversy Over the Cambrian Explosion, provides some excellent references for rebutting this hoary old myth:
The fossil evidence ... does not support this hypothesis. First, as Harvard paleontologist Stephen Jay Gould and Cambridge paleontologist Simon Conway Morris have pointed out, the majority of Cambrian explosion fossils are soft-bodied (Stephen Jay Gould, Wonderful Life [New York: Norton, 1989]; Simon Conway Morris, The Crucible of Creation [Oxford: Oxford University Press, 1998). Second, the fossil evidence points to the appearance of many new body plans in the Cambrian, not just the acquisition of hard parts by existing phyla. According to Berkeley paleontologist James Valentine, the Cambrian explosion "involved far more major animal groups than just the durably skeletonized living phyla." It was "new kinds of organisms, and not old lineages newly donning skeleton-armor, that appeared" (Excerpt C, p. 533). Valentine concluded: "the record that we have is not very supportive of models that posit a long period of the evolution of metazoan phyla" before the Cambrian (Excerpt C, p. 547).
References
|
|
Objection: Hasn't the discovery of Precambrian animal fossils solved the problem of the Cambrian explosion? Reply: No, for two reasons. First, most of the 30-plus major groups (phyla) of animals appeared relatively suddenly, in the Cambrian period; there are no traces of these groups in Precambrian fossils. It is generally acknowledged among scientists that most of the 30-plus major groups of animals have no precedents before the beginning of the Cambrian period, 542 million years ago, as the Darwin's Dilemma FAQ, Questions about the Cambrian Explosion, Evolution, and Intelligent Design, points out in its reply to Question 2:
That the precursors to the Cambrian groups are indeed missing from the record is widely accepted among paleontologists; thus, this is not the controversial aspect of the ID position. About the missing precursors at the base of the tree of the animal phyla, Valentine notes: Second, Precambrian animals were much simpler than Cambrian animals. They would have lacked the hierarchical patterns of protein regulation that are found in complex animals. Dr. Stephen Meyer, P. A. Nelson, and Paul Chien provides an excellent description of the sudden increase in animal complexity during the Cambrian explosion in their 2001 paper, The Cambrian Explosion: Biology's Big Bang (later published in Darwinism, Design, and Public Education, Michigan State University Press, 2004):
One way to measure the increase in the complexity of the animals that appeared in the Cambrian is to assess the number of cell types that are required to build such animals and to compare that number with those creatures that went before.(19) Functionally more complex animals require more cell types to perform their more diverse functions. Each new cell type requires many new and specialized proteins. New proteins in turn require new genetic information encoded in DNA. Thus, an increase in the number of cell types implies (at a minimum) a considerable increase in the amount of specified genetic information. For example, molecular biologists have recently estimated that a minimally complex cell would require between 318 to 562 kilobase pairs of DNA to produce the proteins necessary to maintain life.(20) Yet to build the proteins necessary to sustain a complex arthropod such as a trilobite would require an amount of DNA greater by several orders of magnitude (e.g., the genome size of the worm Caenorhabditis elegans is approximately 97 million base pairs(21) while that of the fly Drosophila melanogaster (an arthropod), is approximately 120 million base pairs.(22) For this reason, transitions from a single cell to colonies of cells to complex animals represent significant (and in principle measurable) increases in complexity and information content. Even C. elegans, a tiny worm about one millimeter long, comprises several highly specialized cells organized into unique tissues and organs with functions as diverse as gathering, processing and digesting food, eliminating waste, external protection, internal absorption and integration, circulation of fluids, perception, locomotion and reproduction. The functions corresponding to these specialized cells in turn require many specialized proteins, genes and cellular regulatory systems, representing an enormous increase in specified biological complexity... Cambrian animals required 50 or more different cell types to function, whereas sponges required only 5 cell types. |
|
Objection: The Cambrian explosion didn't happen overnight. It took 20 million years. Some explosion! Reply: The real point at issue is not whether the Cambrian explosion was instantaneous, but whether blind processes are capable of generating complex animals in the relatively short time available (20 million years). All the available evidence indicates that they're not.
|
|
Objection: Don't mutations in the genes controlling development (such as Hox genes), explain how new bodyplans evolved? Reply: No. Mutations in the genes controlling developing development are especially lethal, as the Darwin's Dilemma FAQ, Questions about the Cambrian Explosion, Evolution, and Intelligent Design, points out, in its reply to Question 3:
Animals do not tolerate mutations to genes involved in regulating bodyplan construction. Objection: But couldn't circumstances have been different in the past, to allow for the rapid evolution of novel bodyplans from a common ancestor? Reply: The Darwin's Dilemma FAQ, Questions about the Cambrian Explosion, Evolution, and Intelligent Design, exposes the unsupported speculation that lies behind this objection. Here is an excerpt from the reply to Question 7:
Well, maybe. But why think this? What is the evidence? ...
|
|
Objection: If an Intelligent Designer was responsible for the Cambrian explosion, why would He have taken so long to bring it about? Why take 20 million years? Why not do it instantly? Reply: This objection assumes that an Intelligent Designer who engineered the Cambrian explosion would have wanted it to happen overnight. That's a theological objection, not a scientific one. And in any case, it's highly doubtful. Here are two fairly obvious reasons why a Designer would not have wanted complex animals to appear overnight. (a) Terra-forming. Complex animals have their own specialized physiological needs, to support their uniquely active way of life. Some changes in the Earth's environment may have been required before complex animals could appear. For instance, recent research suggests that volcanically active midocean ridges caused a massive and sudden surge of the calcium concentration in the oceans, making it possible for marine organisms to build skeletons and hard body parts for the first time. (See Xavier Fernandez-Busquets, Andre Kornig, Iwona Bucior, Max M. Burger, and Dario Anselmetti. Self-Recognition and Ca2+-Dependent Carbohydrate-Carbohydrate Cell Adhesion Provide Clues to the Cambrian Explosion. Molecular Biology and Evolution, 2009; 26 (11): 2551.) Geological transformations take time to attain chemical equilibrium. Lest anyone think that this calcium upsurge "explains" the Cambrian explosion: it should be borne in mind that a necessary condition is not the same as a sufficient condition. Calcium upsurges don't explain how hierarchical patterns of protein regulation suddenly arose in animals from that time. (b) Ecological engineering. The appearance of complex animals would have added to the complexity of ecosystems. There would have been an increase in the number of needs that the first bilaterian animals had to meet, as complex ecological interactions developed. (See Marshall, C.R. (2006). Explaining the Cambrian "Explosion" of Animals. Annual Review of Earth and Planetary Sciences, Vol. 34: 355-384. DOI: 10.1146/annurev.earth.33.031504.103001. ) It takes time to set up a self-sustaining food chain. Once again: ecological explanations of the Cambrian explosion are well suited to explaining why there had to have been a rapid increase in both disparity and diversity, but by themselves, they cannot explain why the "explosion" happened when it did. Nor can they explain how hierarchical patterns of protein regulation suddenly arose in animals from that time. Objection: These are ad hoc arguments, which perfectly illustrates why Intelligent Design isn't science. You can prove anything you want using arguments like that. Reply: No, you can't. Intelligent Design arguments are precise where they need to be. They give us clear quantitative criteria for determining which systems in Nature must have been intelligently designed. Briefly, we can be certain beyond reasonable doubt that systems in Nature which are capable of performing a specific function, and whose likelihood of originating as a result of blind processes (chance plus necessity) is less than 1 in 10 to the power of 150, must have been designed by an Intelligent Agent. That's all we need to be precise about: which systems can be shown to have been intelligently designed, and which cannot. The other questions you might want to ask about a Designer - who, when, where, why and how - are icing on the cake. You can speculate all you like about those questions, but that doesn't affect the central, scientifically established fact that some biological systems were intelligently designed.
|
C. A Sixth Argument Against Darwinian Evolution: Whale Evolution and the Problem of Time

A humpback whale breaching. Image courtesy of Whit Welles and Wikipedia.
Even if Darwinian evolution proved to be capable of effecting large-scale evolutionary changes, this would not be enough to show that it accounts for the origin of species. To do that, one would also have to show that Darwinian evolution can bring about these changes within the time available. The example of whale evolution provides a striking illustration of why there isn't enough time for Darwinian evolution to do its work, and why only intelligently directed evolution could have accomplished the transformation from a land-dwelling animal to a fully aquatic whale within the time available.
Whale evolution poses a particular problem for Darwinists, because it requires multiple co-ordinated mutations to have occurred in parallel in the ancestors of modern whales, over a relatively short time frame of a few million years. These problems were admirably summarized by Uncommon Descent contributor Jonathan M. in a recent post entitled, A Whale of a Problem for Evolution: Ancient Whale Jawbone Found in Antartica (14 October 2011). Allow me to quote an excerpt:
As many readers will doubtless be aware, the evolution of the whale has previously raised substantial problems because of the extremely abrupt timescale over which it occurred. Evolutionary Biologist Richard von Sternberg has previously applied the population genetic equations employed in a 2008 paper by Durrett and Schmidt to argue against the plausibility of the transition happening in such a short period of time. Indeed, the evolution of Dorudon and Basilosaurus (38 mya) from Pakicetus (53 mya) has been previously compressed into a period of less than 15 million years.
Previously, the whale series looked something like this:
Such a transition is a fete of genetic rewiring and it is astonishing that it is presumed to have occurred by Darwinian processes in such a short span of time. This problem is accentuated when one considers that the majority of anatomical novelties unique to aquatic cetaceans (Pelagiceti) appeared during just a few million years – probably within 1-3 million years. The equations of population genetics predict that – assuming an effective population size of 100,000 individuals per generation, and a generation turnover time of 5 years (according to Richard Sternberg's calculations and based on equations of population genetics applied in the Durrett and Schmidt paper), that one may reasonably expect two specific co-ordinated mutations to achieve fixation in the timeframe of around 43.3 million years. When one considers the magnitude of the engineering feat, such a scenario is found to be devoid of credibility. Whales require an intra-abdominal counter current heat exchange system (the testis are inside the body right next to the muscles that generate heat during swimming), they need to possess a ball vertebra because the tail has to move up and down instead of side-to-side, they require a re-organisation of kidney tissue to facilitate the intake of salt water, they require a re-orientation of the fetus for giving birth under water, they require a modification of the mammary glands for the nursing of young under water, the forelimbs have to be transformed into flippers, the hindlimbs need to be substantially reduced, they require a special lung surfactant (the lung has to re-expand very rapidly upon coming up to the surface), etc etc.
The problem of whale evolution has just gotten a whole lot worse. The window of time available for whale evolution has shrunk from 15 million years to just 4 million years, thanks to the discovery of a 49 million-year-old fully aquatic whale in Antarctica, reported by MSNBC.com (11 October 2011):
BUENOS AIRES, Argentina — The jawbone of an ancient whale found in Antarctica may be the oldest fully aquatic whale yet discovered, Argentine scientists said Tuesday.A scientist not involved in the find said it could suggest that whales evolved much more quickly from their amphibian precursors than previously thought.
Argentine paleontologist Marcelo Reguero, who led a joint Argentine-Swedish team, said the fossilized archaeocete jawbone found in February dates back 49 million years. In evolutionary terms, that's not far off from the fossils of even older proto-whales from 53 million years ago that have been found in South Asia and other warmer latitudes.
Those earlier proto-whales were amphibians, able to live on land as well as sea. This jawbone, in contrast, belongs to the Basilosauridae group of fully aquatic whales, said Reguero, who leads research for the Argentine Antarctic Institute.
University of Chicago paleontologist Paul Sereno said that if the identification of the new find is confirmed, it will suggest that "archaeocetes evolved much more quickly than previously thought from their semi-aquatic origin in present-day India and Pakistan."
Jonathan M. highlights the embarrassment to Darwinian evolutionists caused by the new find:
This substantially reduces the window of time in which the Darwinian mechanism has to accomplish truly radical engineering innovations and genetic rewiring to perhaps just five million years — or perhaps even less. It also suggests that this fully aquatic whale existed before its previously-thought-to-be semi-aquatic archaeocetid ancestors.
Objection: Why didn't the Designer make modern whales instantaneously, instead of taking millions of years?
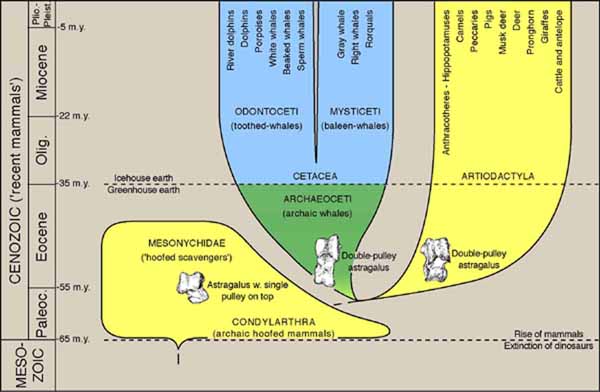
Phylogeny of whales (order Cetacea), showing a common ancestry shared with the Artiodactyla (even-toed hoofed animals), and also the hypothesized evolutionary origin of both from older Paleocene-age Condylarthra. The horizontal axis is arbitrary, while the vertical axis represents geological time. The discovery of distinctively artiodactyl-like double-pulley astragalus bones in articulated skeletons of early archaeocetes is the principal evidence linking whales and artiodactyls, as shown here (see Gingerich et al., 2001). The evolutionary origin of both whales and artiodactyls is closely tied to the Paleocene-Eocene boundary, and the transition from archaeocetes to modern whales is related to climatic and ocean circulation changes at the Eocene-Oligocene boundary. Source: University of Michigan Museum of Paleontology. (See http://www-personal.umich.edu/~gingeric/PDGwhales/Whales.htm.) Figure may be reproduced for non-profit educational use.
One sometimes hears the following argument from critics of Intelligent Design: "If you believe that whales are descended from land animals, and that the process was engineered by an Intelligent Design, why didn't He perform the transformation from a land animal to a whale instantaneously, instead of taking ten million years?"
In reply: the question contains a theological assumption, that any Intelligent Designer of life would have wanted to produce modern whales instantaneously, if at all. But this is highly doubtful, for a number of reasons.
First, the question assumes that a modern whale would have been able to out-compete a transitional forms if it were alive back then, which is doubtful, as some of these were amphibious, living on the land as well as in the sea.
Second, it assumes that there were no environmental conditions 53 million years ago, that would have been unfavorable to modern whales, despite the fact that there was actually a very marked climate change 35 million years ago, from a "greenhouse Earth" to an "icehouse Earth."
Third, it assumes that there would have been suitable food for modern whales in the oceans, back in those times.
Fourth, it assumes that the sudden appearance of whales 53 million years ago would not have caused any major ecological disruptions – which is quite an assumption to make, when some scientists are now telling us that a tiny increase (in absolute terms) in atmospheric carbon dioxide levels, from 0.04% to 0.08%, will eventually result in the extinction of a quarter of the world's species (and perhaps more).
Finally, it assumes that an ancestral land animal could have given birth to a modern whale produced by intelligently designed genetic engineering, without dying in the process! :)
D. "But there's plenty of time for evolution!" - Only if it's intelligently designed evolution!
A recent paper by Herbert S. Wilf and Warren J. Ewens, entitled, There's plenty of time for evolution (Proceedings of the National Academy of Sciences, December 28 2010, vol. 107 no. 52, pp. 22454-22456, doi: 10.1073/pnas.1016207107) claims to show that there's plenty of time for Darwinian evolution to occur, even if multiple mutations are required:
AbstractObjections to Darwinian evolution are often based on the time required to carry out the necessary mutations. Seemingly, exponential numbers of mutations are needed. We show that such estimates ignore the effects of natural selection, and that the numbers of necessary mutations are thereby reduced to about K log L, rather than K [to the power of] L, where L is the length of the genomic "word," and K is the number of possible "letters" that can occupy any position in the word. The required theory makes contact with the theory of radix-exchange sorting in theoretical computer science, and the asymptotic analysis of certain sums that occur there.
Excerpt:
Evolution is an "in parallel" process, with beneficial mutations at one gene locus being retained after they become fixed in a population while beneficial mutations at other loci become fixed. In fact this statement is essentially the principle of natural selection...
The paradigm used in the incorrect argument [against Darwinian evolution - VJT] is often formalized as follows: Suppose that we are trying to find a specific unknown word of L letters, each of the letters having been chosen from an alphabet of K letters. We want to find the word by means of a sequence of rounds of guessing letters. A single round consists in guessing all of the letters of the word by choosing, for each letter, a randomly chosen letter from the alphabet. If the correct word is not found, a new sequence is guessed, and the procedure is continued until the correct sequence is found. Under this paradigm the mean number of rounds of guessing until the correct sequence is found is indeed K [to the power of] L.
But a more appropriate model is the following: After guessing each of the letters, we are told which (if any) of the guessed letters are correct, and then those letters are retained. The second round of guessing is applied only for the incorrect letters that remain after this first round, and so forth. This procedure mimics the "in parallel" evolutionary process. The question concerns the statistics of the number of rounds needed to guess all of the letters of the word successfully.
The fact is that with the parallel model, i.e., taking account of natural selection, the number of rounds of mutations that are needed to change the complete genome to its desirable form are only about K log L, instead of the hugely exponential K [to the power of] L which would result from the serial model.
A response to Wilf and Ewens' paper was rapidly forthcoming from Dr. Douglas Axe, of the Biologic Institute. In a short post mockingly titled, Breaking News from the Academy: There's Plenty of Time for Evolution! (January 14, 2011), Dr. Axe pointed out the fallacious logic employed by Wilf and Ewens in their paper:
Lacking recourse to anything comparably compelling, Darwinists have always relied heavily on mere repetition of their core beliefs. If you can’t prove something, sometimes you just keep asserting it with an authoritative tone in prominent places, hoping that it will catch on. From what I can tell, that appears to be the most plausible explanation for a paper by Herbert Wilf and Warren Ewens titled "There's Plenty of Time for Evolution", which just appeared in the highly regarded Proceedings of the National Academy of Sciences [1]...So here we have a new research paper that reads very much like a mathematically embellished version of the simplistic "METHINKS IT IS LIKE A WEASEL" argument put forward twenty-five years ago by Richard Dawkins [2]. In case you missed it the first time around, here's my two-sentence synopsis. Although it would take eons for unassisted random typing to generate the Shakespearean line METHINKS IT IS LIKE A WEASEL, the task becomes very manageable if something can select the best line from among the many lines of random gibberish, where 'best' means most resembling METHINKS IT IS LIKE A WEASEL (however slight that resemblance may be). Couple this with the ability to breed slight variations on what was just selected, and voilá!— a line from Shakespeare materializes right before our eyes.
It's an old argument with an embarrassingly obvious flaw. Yes, meaningful text can evolve very rapidly if selection has foresight or (equivalently) if miraculously helpful fitness functions can be assumed. But alas, neither of these happy circumstances follows from the impersonal kind of selection that Darwinists are committed to.
Dawkins' illustration makes this abundantly clear, in spite of his intent. He proposed (in my antique copy of his book, it’s on page 48) that this:
WDLTMNLT DTJBSWIRZREZLMQCOPis somehow manifestly more fit than this:
WDLMNLT DTJBKWIRZREZLMQCOPbut I can't imagine why it would be, unless the selector (like Dawkins) knows exactly where he wants to go with it. If he does... well, that's called intelligent design.
In the end, whether evolution has plenty of time or not depends on what you want to ascribe to it. It copes well with the most favorable adaptations conceivable (those offering substantial benefit after a single nucleotide substitution), but even slightly more complex tasks involving just two or three mutations can easily stump it [3,4]. The key question, then, is this: What, of all life's marvels, can be accounted for in terms of the single-change adaptations that Darwinism explains? And the answer, if we take Dawkins' illustration seriously, is: Nothing that approaches the complexity of a six-word sentence.
You don't need a biology degree to see that this leaves Darwinism in a difficult position. In fact, oddly enough, it seems that biology degrees only make it harder to see.
[1] doi:10.1073/pnas.1016207107
[2] http://isbndb.com/d/book/the_blind_watchmaker_a05.html
[3] doi:10.5048/BIO-C.2010.2
[4] doi:10.5048/BIO-C.2010.4
Recommended Reading
The two papers ([3] and [4]) cited by Dr. Axe at the end of his above-cited post, Breaking News from the Academy: There's Plenty of Time for Evolution! (January 14, 2011), are as follows:
Reductive Evolution Can Prevent Populations from Taking Simple Adaptive Paths to High Fitness by Ann K. Gauger, Stephanie Ebnet, Pamela F. Fahey and Ralph Seelke (BIO-Complexity, 2010(2):1-9, doi:10.5048/BIO-C.2010.2):
AbstractNew functions requiring multiple mutations are thought to be evolutionarily feasible if they can be achieved by means of adaptive paths - successions of simple adaptations each involving a single mutation. The presence or absence of these adaptive paths to new function therefore constrains what can evolve. But since emerging functions may require costly over-expression to improve fitness, it is also possible for reductive (i.e., cost-cutting) mutations that eliminate over-expression to be adaptive. Consequently, the relative abundance of these kinds of adaptive paths -- constructive paths leading to new function versus reductive paths that increase metabolic efficiency -- is an important evolutionary constraint. To study the impact of this constraint, we observed the paths actually taken during long-term laboratory evolution of an Escherichia coli strain carrying a doubly mutated trpA gene. The presence of these two mutations prevents tryptophan biosynthesis. One of the mutations is partially inactivating, while the other is fully inactivating, thus permitting a two-step adaptive path to full tryptophan biosynthesis. Despite the theoretical existence of this short adaptive path to high fitness, multiple independent lines grown in tryptophan-limiting liquid culture failed to take it. Instead, cells consistently acquired mutations that reduced expression of the double-mutant trpA gene. Our results show that competition between reductive and constructive paths may significantly decrease the likelihood that a particular constructive path will be taken. This finding has particular significance for models of gene recruitment, since weak new functions are likely to require costly over-expression in order to improve fitness. If reductive, cost-cutting mutations are more abundant than mutations that convert or improve function, recruitment may be unlikely even in cases where a short adaptive path to a new function exists.
The Limits of Complex Adaptation: An Analysis Based on a Simple Model of Structured Bacterial Populations by Douglas Axe (BIO-Complexity, 2010(4):1-10, doi:10.5048/BIO-C.2010.4):
AbstractTo explain life's current level of complexity, we must first explain genetic innovation. Recognition of this fact has generated interest in the evolutionary feasibility of complex adaptations--adaptations requiring multiple mutations, with all intermediates being non-adaptive. Intuitively, one expects the waiting time for arrival and fixation of these adaptations to have exponential dependence on d, the number of specific base changes they require. Counter to this expectation, Lynch and Abegg have recently concluded that in the case of selectively neutral intermediates, the waiting time becomes independent of d as d becomes large. Here, I confirm the intuitive expectation by showing where the analysis of Lynch and Abegg erred and by developing new treatments of the two cases of complex adaptation--the case where intermediates are selectively maladaptive and the case where they are selectively neutral. In particular, I use an explicit model of a structured bacterial population, similar to the island model of Maruyama and Kimura, to examine the limits on complex adaptations during the evolution of paralogous genes--genes related by duplication of an ancestral gene. Although substantial functional innovation is thought to be possible within paralogous families, the tight limits on the value of d found here (d less than or equal to 2 for the maladaptive case, and d less than or equal to 6 for the neutral case) mean that the mutational jumps in this process cannot have been very large. Whether the functional divergence commonly attributed to paralogs is feasible within such tight limits is far from certain, judging by various experimental attempts to interconvert the functions of supposed paralogs. This study provides a mathematical framework for interpreting experiments of that kind, more of which will needed before the limits to functional divergence become clear.
References Cited in Casey Luskin's article on Molecular Machines (see above)
[1.] See Marco Piccolino, “Biological machines: from mills to molecules,” Nature Reviews Molecular Cell Biology, Vol. 1:149-153 (November, 2000).
[2.] Marco Piccolino, “Biological machines: from mills to molecules,” Nature Reviews Molecular Cell Biology, Vol. 1:149-153 (November, 2000).
[3.] Thomas Köcher & Giulio Superti-Furga, "Mass spectrometry-based functional proteomics: from molecular machines to protein networks," Nature Methods, Vol. 4(10):807-815 (October, 2007).
[4.] Tinh-Alfredo V. Khuong, Jose E. Junez, Carlos E. Godinez, and Miguel A. Garcia-Garibay, "Crystalline Molecular Machines: A Quest Toward Solid-State Dynamics and Function," Accounts of Chemical Research, Vol. 39(6):413-422 (2006).
[5.] C. Mavroidis, A. Dubey, and M.L. Yarmush, "Molecular Machines," Annual Review of Biomedical Engineering, Vol. 6:363-395 (2004).
[6.] See "The Closest Look Ever At The Cell's Machines,” ScienceDaily.com (January 24, 2006).
[9.] Bruce Alberts, "The Cell as a Collection of Protein Machines: Preparing the Next Generation of Molecular Biologists," Cell, Vol. 92:291 (February 6, 1998).
[10.] Marco Piccolino, “Biological machines: from mills to molecules,” Nature Reviews Molecular Cell Biology, Vol. 1:149-153 (November, 2000).
[27.] Thomas R. Cech, “Crawling Out of the RNA World,” Cell, Vol. 136:599-602 (February 20, 2009).
[28.] Jonathan P Staley and John L Woolford, Jr, “Assembly of ribosomes and spliceosomes: complex ribonucleoprotein machines,” Current Opinion in Cell Biology, Vol. 21(1):109-118 (February, 2009).
[29.] “Life: What A Concept!” (The Edge Foundation, 2008).
[34.] Markus C. Wahl, Cindy L. Will, and Reinhard Lührmann, "The Spliceosome: Design Principles of a Dynamic RNP Machine," Cell, Vol. 136: 701-718 (February 20, 2009).
[35.] Samuel E. Butcher, “The spliceosome as ribozyme hypothesis takes a second step,” Proceedings of the U.S. National Academy of Sciences, Vol. 106(30):12211-12212 (July 28, 2009).
[36.] Timothy W. Nilsen, "The spliceosome: the most complex macromolecular machine in the cell?," BioEssays, Vol. 25:1147-1149 (2003).
[37.] See David Goodsell, “The ATP Synthase,” Molecule of the Month at Protein Data Bank (December, 2005).
[38.] C. Mavroidis, A. Dubey, and M.L. Yarmush, "Molecular Machines," Annual Review of Biomedical Engineering, Vol. 6:363-395 (2004); Paul D. Boyer, "The ATP Synthase--A Splendid Molecular Machine," Vol. 66:717-749 (1997); Steven M. Block, "Real engines of creation," Nature, Vol. 386:217-219 (March 20, 1997).
[50.] Henrike C. Besche, Andreas Peth, and Alfred L. Goldberg, “Getting to First Base in Proteasome Assembly,” Cell, Vol. 138:25-28 (July 10, 2009).
[51.] Wolfgang Baumeister, Jochen Walz, Frank Zu¨hl, and Erika Seemu¨ller, “The Proteasome: Paradigm of a Self-Compartmentalizing Protease,” Cell, Vol. 92:367-380 (February 6, 1998).
[73.] Jennifer Turner, Manju M. Hingorani, Zvi Kelman, and Mike O’Donnell, "The internal workings of a DNA polymerase clamp-loading machine," The EMBO Journal, Vol.18:771-783 (1999); “DNA Polymerase: an Active Machine,” The Journal of Biological Chemistry, Vol. 282:e99940 (September 28, 2007).
[74.] Paul J. Rothwell and Gabriel Waksman, "A Pre-equilibrium before Nucleotide Binding Limits Fingers Subdomain Closure by Klentaq1," The Journal of Biological Chemistry, Vol. 282(39):28884-28892 (September 28, 2007).
[75.] See David Goodsell, “DNA Polymerase,” Molecule of the Month at Protein Data Bank (March, 2000).
[76.] Jennifer Turner, Manju M. Hingorani, Zvi Kelman, and Mike O’Donnell, "The internal workings of a DNA polymerase clamp-loading machine," The EMBO Journal, Vol.18:771-783 (1999).
[77.] See David Goodsell, “DNA Polymerase,” Molecule of the Month at Protein Data Bank (March, 2000).
[80.] Steven Henikoff, Kami Ahmad, Harmit S. Malik, “The Centromere Paradox: Stable Inheritance with Rapidly Evolving DNA,” Science, Vol. 293:1098-1102 (August 10, 2001).
[81.] Ajit Joglekar, Kerry Bloom, and E. D. Salmon, "In vivo protein architecture of the eukaryotic kinetochore with nanometer scale accuracy," Current Biology, Vol. 19(8):694-699 (April 28, 2009).
[82.] Iain M. Cheeseman & Arshad Desai, “Molecular architecture of the kinetochore-microtubule interface,” Nature Reviews Molecular Cell Biology, Vol. 9:33-46 (2008).
[95.] Marco Piccolino, “Biological machines: from mills to molecules,” Nature Reviews Molecular Cell Biology, Vol. 1:149-153 (November, 2000).
[96.] See David Goodsell, “Photosystem I,” Molecule of the Month at Protein Data Bank (October, 2001).
| Table of Contents | Part One | Part Two | Part Three | Part Four | Part Five | Part Six | Part Seven |
| Part Eight | Part Nine | Part Ten | Part Eleven | Part Twelve | Part Thirteen | Part Fourteen | Conclusion |